Naive Bayes - Supervised Image Classification
In this lesson we will learn about Naïve Bayes classification models, which use an algorithm that relies on Bayes Theorem, and which is based on strong assumptions concerning the independence of the predictors conditional on the response . Naïve Bayes classification models are commonly used as an alternative to decision trees for classification problems. Naive Bayes classification models are highly scalable, requiring a number of parameters linear in the number of variables (features/predictors) in a learning problem . In training the models, maximum-likelihood methods are used to evaluate a closed-form expression .
Load R packages
library(rgdal) # spatial data processing
library(raster) # raster processing
library(plyr) # data manipulation
library(dplyr) # data manipulation
library(RStoolbox) # Image analysis & plotting spatial data
library(RColorBrewer) # color
library(ggplot2) # plotting
library(sp) # spatial data
library(caret) # machine laerning
library(doParallel) # Parallel processing
library(e1071) # Naive BayesThe data could be available for download from here.
# Define data folder
dataFolder<-"D://Dropbox//Spatial Data Analysis and Processing in R//DATA_09//DATA_09//"Load data
train.df<-read.csv(paste0(dataFolder,".\\Sentinel_2\\train_data.csv"), header = T)
test.df<-read.csv(paste0(dataFolder,".\\Sentinel_2\\test_data.csv"), header = T)Start foreach to parallelize for model fitting
mc <- makeCluster(detectCores())
registerDoParallel(mc)Tunning prameters
myControl <- trainControl(method="repeatedcv",
number=3,
repeats=2,
returnResamp='all',
allowParallel=TRUE)Train Naïve Bayes model
We will use the train() function of the caret package with the “method” parameter “nb” wrapped from the e1071 package.
set.seed(849)
fit.nb <- train(as.factor(Landuse)~B2+B3+B4+B4+B6+B7+B8+B8A+B11+B12,
data=train.df,
method = "nb",
metric= "Accuracy",
preProc = c("center", "scale"),
trControl = myControl
)
fit.nb ## Naive Bayes
##
## 16764 samples
## 9 predictor
## 5 classes: 'Building', 'Grass', 'Parking/road/pavement', 'Tree/bushes', 'Water'
##
## Pre-processing: centered (9), scaled (9)
## Resampling: Cross-Validated (3 fold, repeated 2 times)
## Summary of sample sizes: 11175, 11176, 11177, 11175, 11177, 11176, ...
## Resampling results across tuning parameters:
##
## usekernel Accuracy Kappa
## FALSE 0.8746117 0.8337827
## TRUE 0.9062274 0.8754549
##
## Tuning parameter 'fL' was held constant at a value of 0
## Tuning
## parameter 'adjust' was held constant at a value of 1
## Accuracy was used to select the optimal model using the largest value.
## The final values used for the model were fL = 0, usekernel = TRUE
## and adjust = 1.Stop cluster
stopCluster(mc)Confusion Matrix - train data
p1<-predict(fit.nb, train.df, type = "raw")
confusionMatrix(p1, train.df$Landuse)## Confusion Matrix and Statistics
##
## Reference
## Prediction Building Grass Parking/road/pavement Tree/bushes
## Building 2245 0 56 3
## Grass 55 3394 1 46
## Parking/road/pavement 717 0 3789 442
## Tree/bushes 84 88 28 5177
## Water 0 0 0 0
## Reference
## Prediction Water
## Building 0
## Grass 0
## Parking/road/pavement 6
## Tree/bushes 9
## Water 624
##
## Overall Statistics
##
## Accuracy : 0.9084
## 95% CI : (0.904, 0.9128)
## No Information Rate : 0.3381
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 0.8784
##
## Mcnemar's Test P-Value : NA
##
## Statistics by Class:
##
## Class: Building Class: Grass
## Sensitivity 0.7240 0.9747
## Specificity 0.9957 0.9923
## Pos Pred Value 0.9744 0.9708
## Neg Pred Value 0.9408 0.9934
## Prevalence 0.1850 0.2077
## Detection Rate 0.1339 0.2025
## Detection Prevalence 0.1374 0.2085
## Balanced Accuracy 0.8598 0.9835
## Class: Parking/road/pavement Class: Tree/bushes
## Sensitivity 0.9781 0.9134
## Specificity 0.9096 0.9812
## Pos Pred Value 0.7648 0.9612
## Neg Pred Value 0.9928 0.9568
## Prevalence 0.2311 0.3381
## Detection Rate 0.2260 0.3088
## Detection Prevalence 0.2955 0.3213
## Balanced Accuracy 0.9438 0.9473
## Class: Water
## Sensitivity 0.97653
## Specificity 1.00000
## Pos Pred Value 1.00000
## Neg Pred Value 0.99907
## Prevalence 0.03812
## Detection Rate 0.03722
## Detection Prevalence 0.03722
## Balanced Accuracy 0.98826Confusion Matrix - test data
p2<-predict(fit.nb, test.df, type = "raw")
confusionMatrix(p2, test.df$Landuse)## Confusion Matrix and Statistics
##
## Reference
## Prediction Building Grass Parking/road/pavement Tree/bushes
## Building 990 0 18 0
## Grass 27 1456 0 28
## Parking/road/pavement 281 0 1635 181
## Tree/bushes 30 35 7 2220
## Water 0 0 0 0
## Reference
## Prediction Water
## Building 0
## Grass 0
## Parking/road/pavement 6
## Tree/bushes 3
## Water 264
##
## Overall Statistics
##
## Accuracy : 0.9142
## 95% CI : (0.9075, 0.9206)
## No Information Rate : 0.3383
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 0.8861
##
## Mcnemar's Test P-Value : NA
##
## Statistics by Class:
##
## Class: Building Class: Grass
## Sensitivity 0.7455 0.9765
## Specificity 0.9969 0.9903
## Pos Pred Value 0.9821 0.9636
## Neg Pred Value 0.9452 0.9938
## Prevalence 0.1849 0.2076
## Detection Rate 0.1379 0.2028
## Detection Prevalence 0.1404 0.2104
## Balanced Accuracy 0.8712 0.9834
## Class: Parking/road/pavement Class: Tree/bushes
## Sensitivity 0.9849 0.9140
## Specificity 0.9152 0.9842
## Pos Pred Value 0.7775 0.9673
## Neg Pred Value 0.9951 0.9572
## Prevalence 0.2312 0.3383
## Detection Rate 0.2277 0.3091
## Detection Prevalence 0.2929 0.3196
## Balanced Accuracy 0.9501 0.9491
## Class: Water
## Sensitivity 0.96703
## Specificity 1.00000
## Pos Pred Value 1.00000
## Neg Pred Value 0.99870
## Prevalence 0.03802
## Detection Rate 0.03676
## Detection Prevalence 0.03676
## Balanced Accuracy 0.98352Predition at grid location
# read grid CSV file
grid.df<-read.csv(paste0(dataFolder,".\\Sentinel_2\\prediction_grid_data.csv"), header = T)
# Preddict at grid location
p3<-as.data.frame(predict(fit.nb, grid.df, type = "raw"))
# Extract predicted landuse class
grid.df$Landuse<-p3$predict
# Import lnaduse ID file
ID<-read.csv(paste0(dataFolder,".\\Sentinel_2\\Landuse_ID.csv"), header=T)
# Join landuse ID
grid.new<-join(grid.df, ID, by="Landuse", type="inner")
# Omit missing values
grid.new.na<-na.omit(grid.new) Convert to raster
x<-SpatialPointsDataFrame(as.data.frame(grid.new.na)[, c("x", "y")], data = grid.new.na)
r <- rasterFromXYZ(as.data.frame(x)[, c("x", "y", "Class_ID")])Plot Landuse Map:
# Color Palette
myPalette <- colorRampPalette(c("light grey","burlywood4", "forestgreen","light green", "dodgerblue"))
# Plot Map
LU<-spplot(r,"Class_ID", main="Supervised Image Classification: Naïve Bayes" ,
colorkey = list(space="right",tick.number=1,height=1, width=1.5,
labels = list(at = seq(1,4.8,length=5),cex=1.0,
lab = c("Road/parking/pavement" ,"Building", "Tree/buses", "Grass", "Water"))),
col.regions=myPalette,cut=4)
LU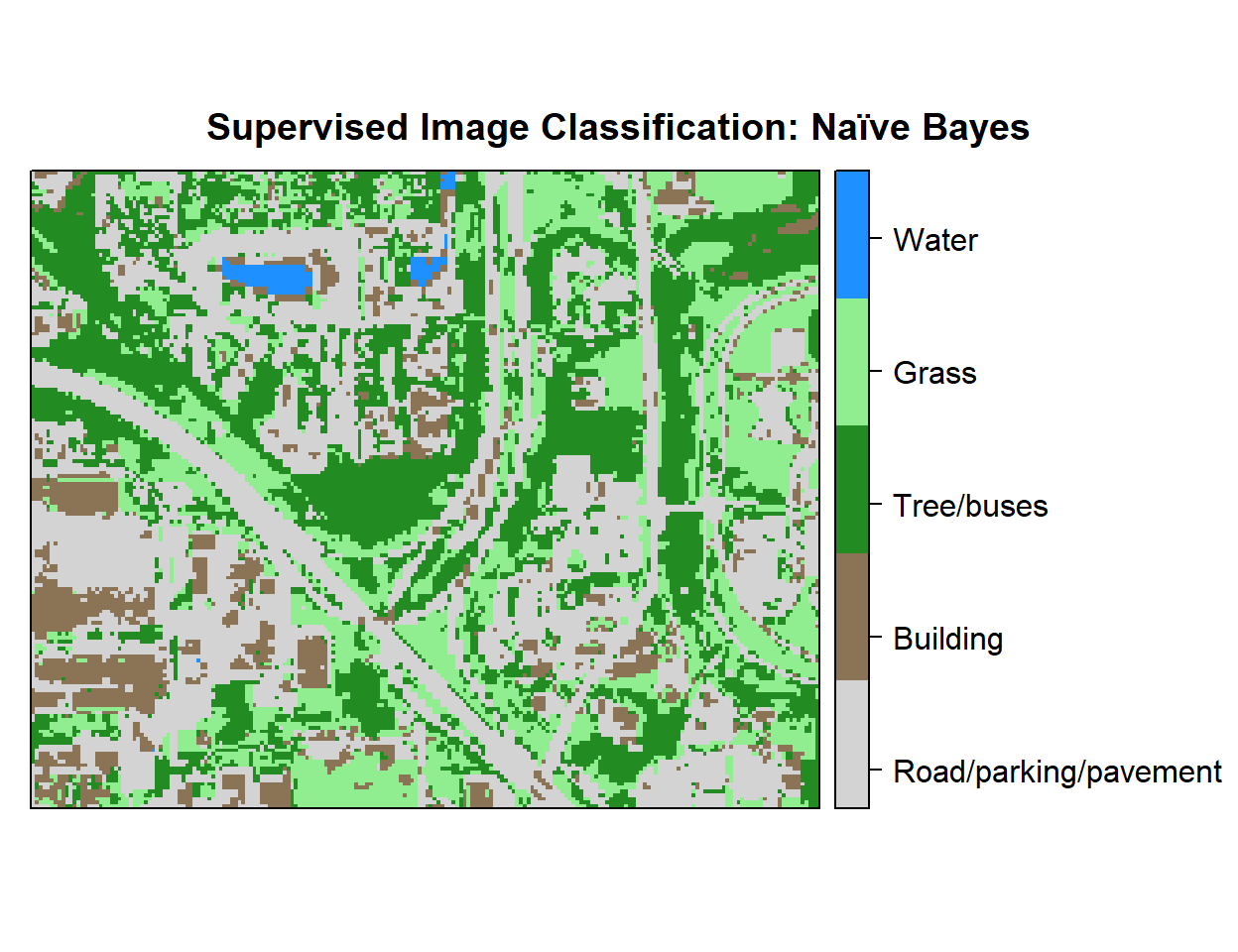
Write raster
# writeRaster(r, filename = paste0(dataFolder,".\\Sentinel_2\\NB_Landuse.tiff"), "GTiff", overwrite=T)rm(list = ls())