Geographically Weighted Principal Components Analysis (GWPCA)
Principal components analysis (PCA) is commonly used to explain the covariance structure of a (high-dimensional) multivariate data set using only a few components (i.e., provide a low-dimensional alternative). The components are linear combinations of the original variables and provide a better understanding of sources of variation and structure of the data.
In geographical settings, standard PCA, in which the components do not depend on location, may be replaced with a GWPCA (Fotheringham et al. 2002; Lloyd 2010a; Harris et al. 2011a), to account for spatial heterogeneity in the structure of the multivariate data. In doing so, GW PCA can identify regions where assuming the same underlying structure in all locations is inappropriate or over-simplistic. GW PCA can assess: (i) how (effective) data dimensionality varies spatially and (ii) how the original variables influence each spatially-varying component.
Load R packages
library(GWmodel) ### GW models
library(sp) ## Data management
library(spdep) ## Spatial autocorrelation
library(gstat) ## Geostatistics
library(RColorBrewer) ## Visualization
library(classInt) ## Class intervals
library(raster) ## spatial data
library(gridExtra) # Multiple plot
library(ggplot2) # Multiple plotLoad Data
The data could be found here.
# Define data folder
dataFolder<-"D:\\Dropbox\\Spatial Data Analysis and Processing in R\\Data_GWR\\"
COUNTY<-shapefile(paste0(dataFolder,"COUNTY_ATLANTIC.shp"))
state<-shapefile(paste0(dataFolder,"STATE_ATLANTIC.shp"))
df<-read.csv(paste0(dataFolder,"data_atlantic_1998_2012.csv"), header=T)Create a data frame
SPDF<-merge(COUNTY,df, by="FIPS")
names(SPDF)## [1] "FIPS" "ID" "x" "y" "REGION_ID"
## [6] "DIVISION_I" "STATE_ID" "COUNTY_ID" "REGION" "DIVISION"
## [11] "STATE" "COUNTY" "X" "Y" "Rate"
## [16] "POV" "SMOK" "PM25" "NO2" "SO2"Create a data frame for PCA
mf <- SPDF[, c(16:20)]
names(mf)## [1] "POV" "SMOK" "PM25" "NO2" "SO2"PCA
First we will PCA with scaled data of somoking, poverty PM25, NO2 and SO2.
data.scaled <- scale(as.matrix(mf@data[, 1:5]))
pca <- princomp(data.scaled, cor = FALSE)
(pca$sdev^2 / sum(pca$sdev^2)) * 100## Comp.1 Comp.2 Comp.3 Comp.4 Comp.5
## 41.303909 26.398439 15.654782 10.733396 5.909474pca$loadings##
## Loadings:
## Comp.1 Comp.2 Comp.3 Comp.4 Comp.5
## POV 0.523 0.353 0.290 0.467 0.548
## SMOK 0.493 0.428 -0.415 0.114 -0.623
## PM25 -0.262 0.584 0.674 -0.221 -0.295
## NO2 -0.550 0.808 -0.168
## SO2 -0.336 0.586 -0.530 -0.258 0.443
##
## Comp.1 Comp.2 Comp.3 Comp.4 Comp.5
## SS loadings 1.0 1.0 1.0 1.0 1.0
## Proportion Var 0.2 0.2 0.2 0.2 0.2
## Cumulative Var 0.2 0.4 0.6 0.8 1.0GW PCA
Create a data-frame with scaled data
coords <- as.matrix(cbind(SPDF$x, SPDF$y))
scaled.spdf <- SpatialPointsDataFrame(coords, as.data.frame(data.scaled ))bw.gw.pca <- bw.gwpca(scaled.spdf,
vars = colnames(scaled.spdf@data),
k = 5,
robust = FALSE,
adaptive = TRUE)## Adaptive bandwidth(number of nearest neighbours): 412 CV score: 2.127331e-27
## Adaptive bandwidth(number of nearest neighbours): 256 CV score: 2.272591e-27bw.gw.pca## [1] 412gw.pca<- gwpca(scaled.spdf,
vars = colnames(scaled.spdf@data),
bw=bw.gw.pca,
k = 5,
robust = FALSE,
adaptive = TRUE)Visualized and interpreted GWPCA output
how data dimensionality varies spatially and
how the original variables influence the components.
For the former, the spatial distribution of local PTV for say, the frst two components can be mapped.
# function for calculation pproportion of variance
prop.var <- function(gwpca.obj, n.components) {
return((rowSums(gwpca.obj$var[, 1:n.components]) /rowSums(gwpca.obj$var)) * 100)
}var.gwpca <- prop.var(gw.pca, 3)
mf$var.gwpca <- var.gwpcapolys<- list("sp.lines", as(state, "SpatialLines"), col="grey", lwd=.8,lty=1)
col.palette<-colorRampPalette(c("blue", "sky blue", "green","yellow", "red"),space="rgb",interpolate = "linear")mypalette.4 <- brewer.pal(8, "YlGnBu")
spplot(mf, "var.gwpca", key.space = "right",
col.regions = mypalette.4, cuts = 7,
sp.layout =list(polys),
col="transparent",
main = "Percent Total Variation for Local components 1 to 3")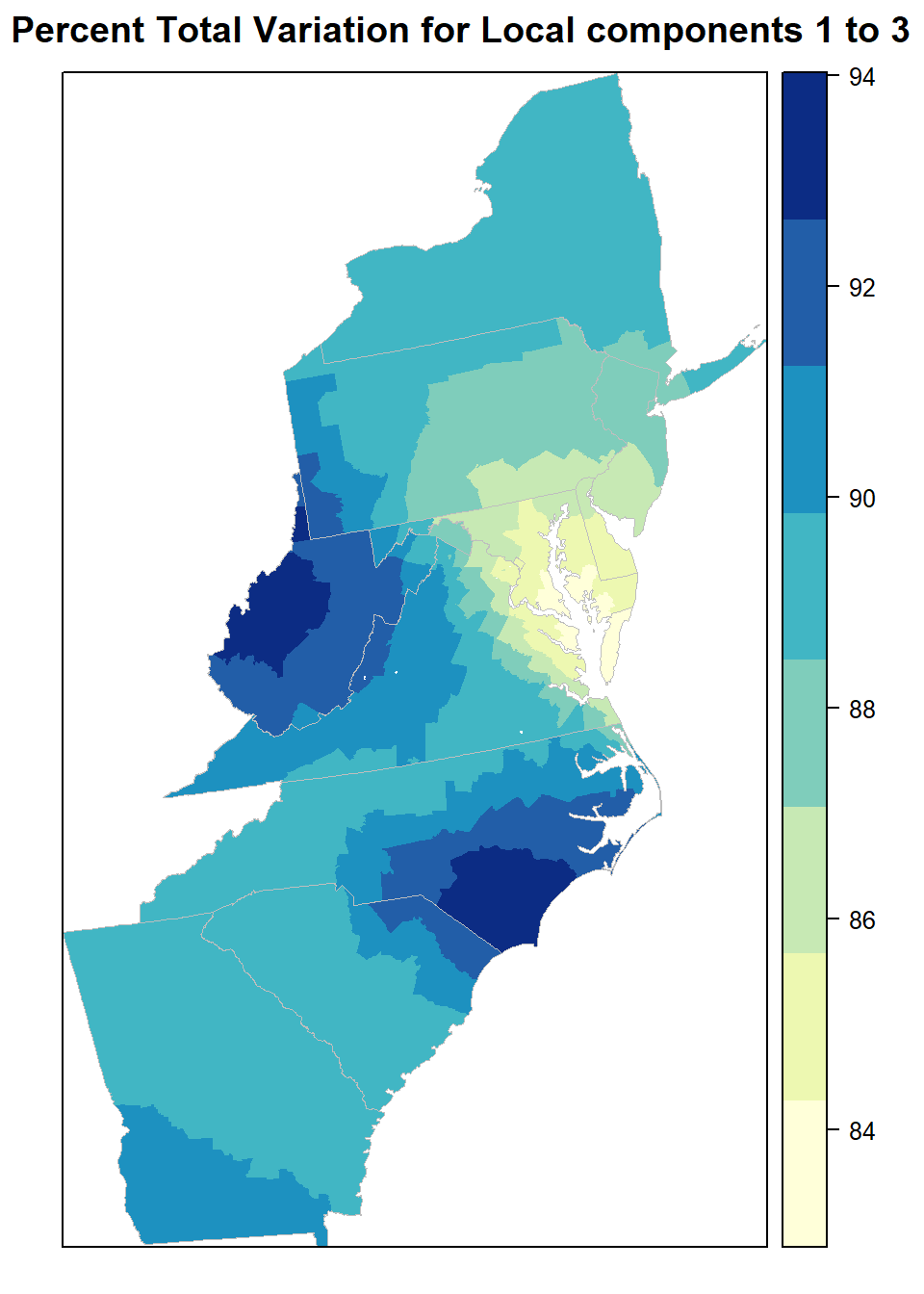
We can next visualize how each of the eight variables locally influence a given component, by mapping the `winning variable’ with the highest absolute loading.
loadings.pc1 <- gw.pca$loadings[, , 1]
win.item = max.col(abs(loadings.pc1))
mf$win.item <- win.itemmypalette.4 <- c("lightpink", "blue", "grey", "purple", "green")
spplot(mf, "win.item", key.space = "right",
col.regions = mypalette.4, at = c(1, 2, 3, 4, 5),
main = "Winning variable: highest \n abs. loading on local Comp.1",
sp.layout =list(polys))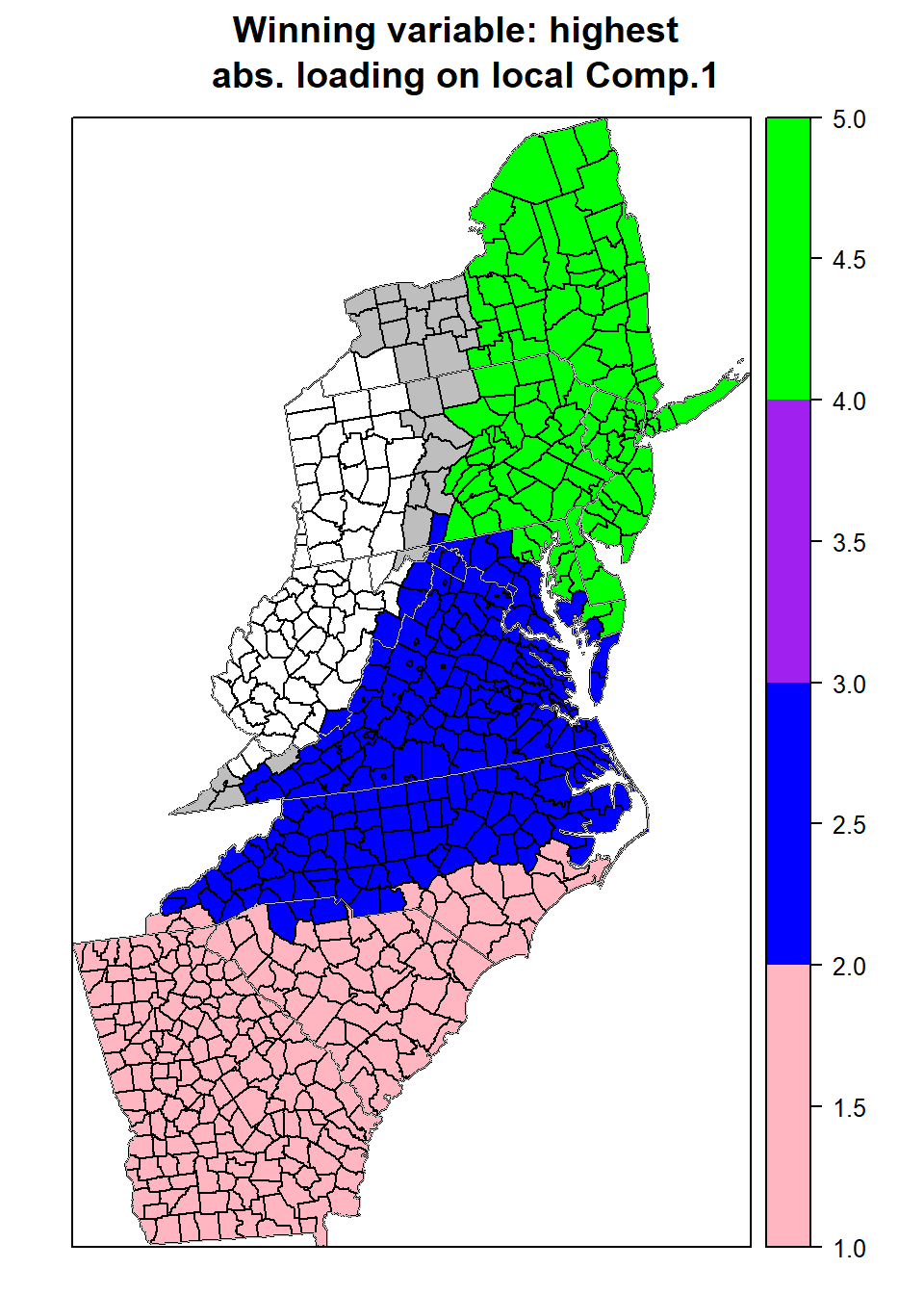
rm(list = ls())